
Sesiunea 9
Disaster Recovery & Business Continuity
ASR, Azure Backup, Front Door, Traffic Manager și arhitecturi cross-region
Introducere
Disaster Recovery & Business Continuity în Azure
Despre acest curs
Ghid complet zero-to-hero: Azure Site Recovery, Azure Backup, storage geo-redundant, RTO vs RPO, arhitecturi cross-region, Front Door și Traffic Manager. Destinat junior cloud engineers, administratori Azure, ingineri de infrastructură și de platformă.
Obiectivele cursului
Explică diferențele
Distinge clar între high availability, backup și disaster recovery — trei concepte frecvent confundate în practică.
Definește RTO și RPO
Recovery Time Objective și Recovery Point Objective pentru orice workload, pornind de la cerințele de business.
Alege modelul corect
Backup, ASR, geo-redundanță, active-active, active-passive — în funcție de context și buget.
Implementează din portal
Configurează din Azure Portal un scenariu coerent de continuitate operațională, de la vault la test failover.
Capitol 1
De ce contează Disaster Recovery și Business Continuity
Trei concepte diferite, adesea confundate
High Availability
O VM cade și pornește rapid pe alt host. Reducerea downtime-ului la nivel local sau zonal. Analogie: airbag și ABS pe aceeași mașină.
Backup
Copie a datelor de ieri. Copie de siguranță pentru restaurare la un punct în timp. Analogie: copii ale documentelor importante într-un seif.
Disaster Recovery
Un întreg serviciu sau datacenter devine indisponibil și tu continui serviciul într-o altă locație. Analogie: muți operațiunea într-un alt sediu.
Un plan bun nu începe cu portalul Azure. Începe cu întrebări de business: ce trebuie să supraviețuiască, cât de repede, cu câtă pierdere de date și cu ce buget?

Capitol 2
Concepte fundamentale: RTO, RPO, failover, failback
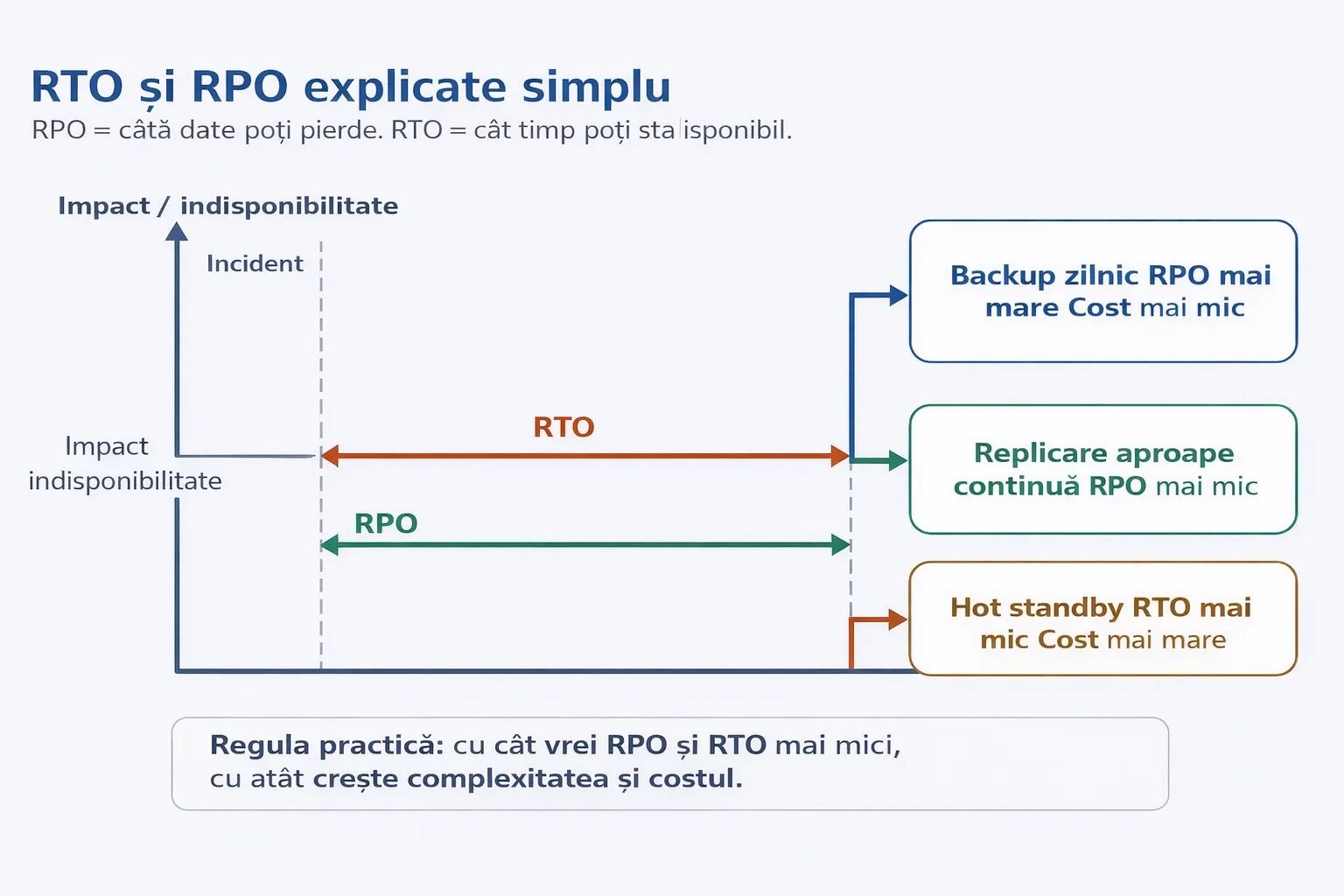
Termeni esențiali DR
Ținte de business și implicații tehnice
| Țintă de business | Exemplu | Implicație tehnică |
|---|---|---|
| RPO = 24h | Poți pierde modificările din ultima zi | Backup periodic; nu suficient pentru aplicații critice |
| RPO = 15 min | Date aproape la zi | Replicare frecventă sau servicii geo-redundante |
| RTO = 8h | Sistemul poate fi offline o parte din zi | Warm standby sau restore orchestrat |
| RTO = 15 min | Aproape fără întrerupere | Arhitectură multi-region, trafic și date pregătite |
Capitol 3
Cum se leagă serviciile Azure între ele
Azure nu are un singur produs care rezolvă tot. Ai nevoie de o combinație de servicii, fiecare cu rolul lui precis. Site Recovery mută workload-uri VM. Backup recuperează date la un punct în timp. Front Door și Traffic Manager mută traficul. Storage geo-redundant protejează datele. Toate se completează, nu se exclud.
Serviciile Azure pentru DR
| Serviciu | Ce rezolvă | Când îl alegi |
|---|---|---|
| Azure Site Recovery | Replicare și failover pentru VM-uri | DR orchestrat pentru mașini virtuale |
| Azure Backup | Backup și restore pe puncte de timp | Retenție, restaurare, protecție ransomware |
| GRS / GZRS | Redundanță a datelor în regiune pereche | Date care trebuie să supraviețuiască unei regiuni |
| Azure Front Door | Failover trafic HTTP/HTTPS global | Aplicații web și API-uri globale |
| Traffic Manager | Failover DNS și routing | Servicii care nu depind de reverse proxy L7 |
| Load Balancer / App GW | Distribuție trafic într-o regiune | Nu sunt substitut pentru DR cross-region |
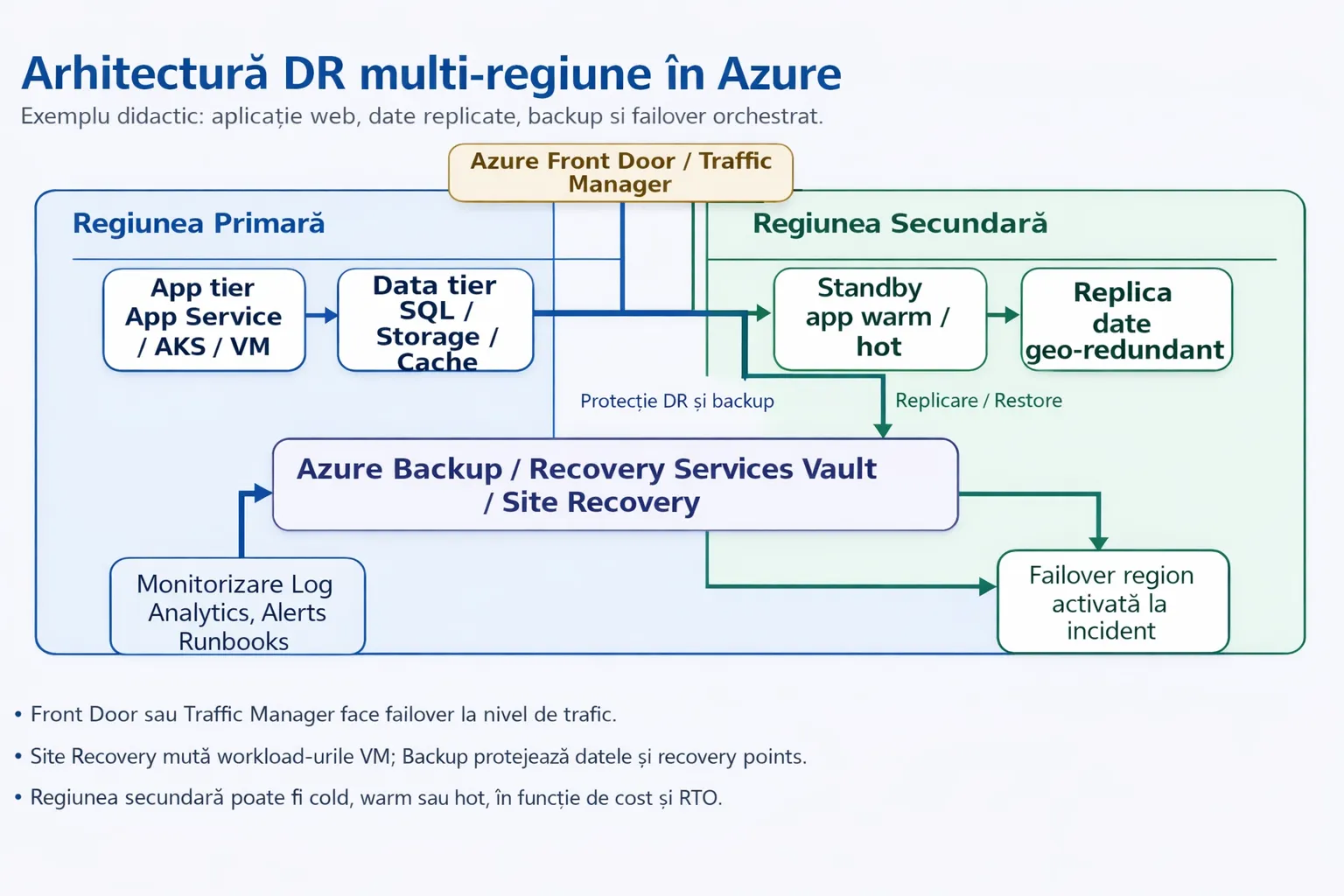
Capitol 4
Azure Site Recovery (ASR) — Deep Dive
Azure Site Recovery este serviciul Azure folosit pentru orchestrarea replicării, failover-ului și failback-ului pentru Azure VMs, mașini on-premises și alte scenarii suportate. Pentru workload-uri hostate în VM-uri, este piesa centrală a DR-ului.

Ce face ASR și ce NU face
Ce face ASR
Configurează replicare sursă → secundar, menține recovery points, orchestrează failover planificat/neplanificat, automatizează ordinea de pornire și scripts.
Ce NU trebuie să ceri de la ASR
Nu este înlocuitor pentru backup pe termen lung. Nu este soluția nativă pentru PaaS web globale. Nu reduce la zero nevoia de runbooks și ownership.
Deploy Azure Site Recovery din portal — pas cu pas
Recovery Services Vault
Creezi sau alegi un Recovery Services vault în regiunea țintă de DR.
Scenariu de replicare
Site Recovery → selectezi Azure to Azure pentru VMs din altă regiune.
Validare permisiuni
Validezi permisiunile, subscription-ul sursă și regiunea țintă.
Configurare target
Resource group țintă, rețeaua, subnet-ul și capacity reservation.
Replication policy
Frecvența recovery points, retention și app-consistent snapshots.
Activare și test failover
Activezi replication, aștepți Protected, rulezi test failover către o rețea izolată.
Insistă pe rețea izolată pentru test failover — validezi recovery fără coliziune cu producția.
Checklist pre-activare ASR
| Verificare | De ce contează | Exemplu |
|---|---|---|
| Target VNet/Subnet | VM-ul trebuie să pornească într-un spațiu IP valid | 10.20.0.0/16 cu subnet dedicat |
| NSG și UDR | Recovery fără conectivitate nu ajută | Acces către DB, DNS, jump host |
| Ordine de pornire | Aplicația pornește doar dacă dependențele există | DB înainte de app |
| Identity și secrete | Serviciul trebuie să se autentifice după failover | Managed identity, Key Vault, DNS |
| Licensing / sizing | Secundarul trebuie să suporte load-ul minim | Warm standby la 50% capacitate |
Capitol 5
Azure Backup și politicile de protecție
Azure Backup răspunde la o întrebare diferită: cum restaurez datele sau mașina la un punct în timp? Nu mută traficul web și nu ține loc de orchestrare DR, dar este o piesă critică în continuitate.
Un backup neverificat este doar o speranță, nu o garanție. Greșeala clasică este să configurezi backup și să nu faci niciodată restore test.
Deploy backup din portal
Recovery Services Vault
Creezi un vault în regiunea principală.
Redundanță potrivită
Ex. GRS pentru reziliență regională.
Selectează tip workload
Azure VM, SQL in Azure VM, Files etc.
Backup policy
Oră, frecvență, retention (zilnică, săptămânală, lunară, anuală).
Selectează resurse și activează
Alegi resursele protejate și activezi backup.
Validează restore points
Efectuezi restaurări de test periodic.
Backup vs Site Recovery — când folosești ce
| Întrebare | Azure Backup | Azure Site Recovery |
|---|---|---|
| Copie la puncte de timp | ✅ Da | Parțial, prin recovery points |
| Failover orchestrat | ❌ Nu | ✅ Da |
| Retenție luni/ani | ✅ Da | ❌ Nu acesta este scopul |
| Testarea mutării workload-ului | Indirect, prin restore | ✅ Da, prin test failover |
Backup și Site Recovery nu se exclud — se completează. Un design matur le folosește pe amândouă.
Capitol 6
Strategii de redundanță pentru date și storage
Modelele de redundanță
LRS (Local Redundant)
Copie locală în aceeași locație. Cost minim, protecție limitată.
ZRS (Zone Redundant)
Copie între zone din aceeași regiune. Bun pentru reziliență zonală.
GRS / GZRS
Copie asincronă într-o regiune pereche. Bun pentru DR regional.
Cross-Region Restore
Restaurare în regiunea secundară pentru backup-uri și servicii suportate.
Protecție recomandată pe tip de workload
| Tip workload | Protecție minimă | Protecție recomandată |
|---|---|---|
| Documente / fișiere | Backup + soft delete | GRS/GZRS + backup + restore test |
| Bază de date critică | Backup automat | HA nativ + geo-redundanță + plan failover |
| VM aplicație business | Backup zilnic | ASR + backup + validare aplicație |
| Site public global | Load balancer local | Front Door + date replicate + secundar pregătit |

Capitol 7
Arhitecturi Cross-Region: Active-Active vs Active-Passive
Două modele fundamentale
Active-Passive
Regiunea principală deservește traficul, secundara este pregătită minimal. Failover doar la incident. Cost mai mic, RTO mai mare. Potrivit pentru: payroll intern, portal raportare, aplicații non-critice.
Active-Active
Ambele regiuni procesează trafic instant. RTO redus semnificativ. Necesită design de date, consistență și observabilitate mai bune. Cost ridicat. Potrivit pentru: checkout, e-commerce, servicii publice critice.
Nu există un răspuns universal. Alegerea depinde de RTO/RPO aprobate de business și de bugetul disponibil.
Capitol 8
Azure Front Door și Traffic Manager pentru DR
Aceste două servicii se ocupă de trafic, nu de backup-ul datelor. Dacă pui Front Door în față, nu ai rezolvat automat replicarea bazei de date sau mutarea VM-urilor. Traficul și datele sunt responsabilități separate.

Front Door vs Traffic Manager
| Criteriu | Front Door | Traffic Manager |
|---|---|---|
| Nivel | HTTP/HTTPS global entry point | DNS-based routing |
| Failover | Rapid, health probes + origin groups | Depinde de TTL/cache DNS |
| WAF / TLS / caching | Da | Nu |
| Scenarii | Web apps, APIs | Mai general, inclusiv non-Azure |
Deploy Azure Front Door — pași clari
Creare profil
Front Door profile Standard sau Premium.
Endpoint public
Punctul de intrare global.
Origin group
Origin primar și secundar.
Health probes
Configurare health probes și load balancing.
Route
Hostname și paths.
Test failover
Oprire controlată a primarului, observare direcționare.
Deploy Traffic Manager — pași clari
Creare profil
Traffic Manager profile în Azure Portal.
Routing method
Priority pentru failover clasic.
DNS și monitor
DNS name, TTL și monitor settings.
Endpoint-uri
Primar și secundar cu priorități corespunzătoare.
Test indisponibilitate
Verificare monitor health și validare failover DNS.
Capitol 9
Runbooks, monitorizare și guvernare operațională
Tehnologia singură nu livrează continuitate. Ai nevoie de monitoring, alertare, roluri clare și proceduri executabile sub presiune.
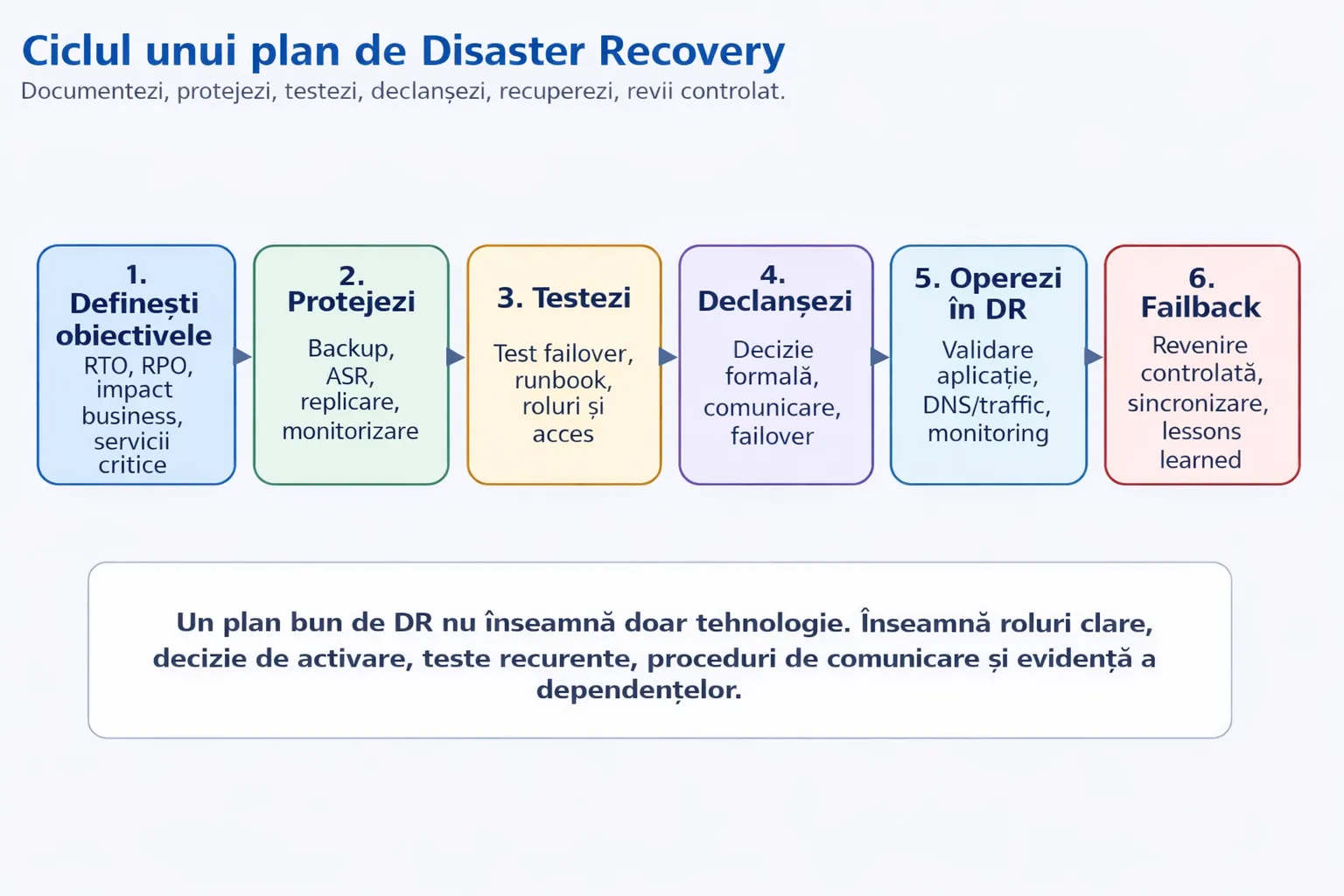
Instrumente de monitorizare și guvernare
Azure Monitor și Alert Rules
Monitorizare continuă a sănătății aplicației și a stării replicării.
Log Analytics
Corelarea incidentelor din multiple surse. Vizibilitate unificată.
Action Groups
Notificare automată către echipa on-call la alertele critice.
Runbooks și Checklist-uri
Proceduri aprobate pentru failover și failback, executabile sub presiune.
Capitol 10
Exemple reale de use cases
Trei scenarii reprezentative
Aplicație internă pe 2 VM-uri + SQL
Compute protejat cu ASR, date cu backup/geo-redundanță, trafic mutat prin Traffic Manager sau DNS.
Portal public multi-region
Front Door cu WAF, două App Services sau AKS în regiuni diferite, date replicate, observabilitate unificată.
On-premises către Azure
ASR replică din datacenter propriu în Azure. Atenție la conectivitate (ExpressRoute/VPN), IP addressing, DNS, acces operator.

Capitol 11
Laborator didactic recomandat
Exerciții practice
| Lab | Obiectiv | Rezultat așteptat |
|---|---|---|
| RTO/RPO workshop | Traduci cerințe business în obiective tehnice | Echipa definește țintele și justifică costul |
| Azure Backup | Configurezi vault și policy, apoi restore test | Demonstrează restore point și verificare |
| ASR pentru VM | Activezi replicare și test failover | Workload-ul pornește în regiunea secundară |
| Front Door / TM | Simulezi indisponibilitatea regiunii primare | Traficul ajunge în secundar |
| Runbook failback | Documentezi pașii de revenire | Checklist clar și ordonat |
Capitol 12
Greșeli frecvente în proiectele de DR
Top greșeli — ce să eviți
Backup confundat cu DR
Backup-ul restaurează date. DR mută întregul serviciu. Sunt complementare, nu interschimbabile.
Identity, DNS și secrete uitate
Un VM pornit fără autentificare funcțională este inutil după failover.
Testare doar a infrastructurii
Un VM pornit nu înseamnă o aplicație funcțională. Testează end-to-end.
Lipsa ownership-ului de activare
Cine decide că se face failover? Cine apasă butonul?
RTO de minute cu buget de laborator
RTO mic costă. Dacă bugetul nu susține arhitectura, RTO-ul nu este realist.
Failback nedocumentat
Echipa știe să plece în DR, dar nu și să revină controlat. Failback neplanificat = pierderi de date.
Capitol 13
Checklist de design pentru arhitect
Validare înainte de producție
Workload-uri critice identificate
Știm exact ce este critic și avem o listă aprobată de business?
RTO și RPO aprobate formal
Aprobate de business, nu doar estimate tehnic?
Protecție separată pe piloni
Compute, date și trafic — nu o soluție unică pentru toate?
Test failover executat recent
Cel puțin un test failover în ultimele 6-12 luni?
Runbook de failback
Documentat și cu un owner operațional desemnat?
Restore test pentru backup-uri
Am testat restore pentru backup-urile critice?
Întrebări de recapitulare
1Care este diferența dintre High Availability, Backup și Disaster Recovery?
HA = reziliență locală/zonală (VM repornește pe alt host). Backup = copie la un punct în timp. DR = mutarea întregului serviciu într-o altă locație la incident regional.
2Ce înseamnă RPO = 15 minute din perspectivă tehnică?
Replicare frecventă sau servicii geo-redundante — datele trebuie sincronizate cel puțin la fiecare 15 minute.
3Când folosești Azure Site Recovery și când Azure Backup?
ASR pentru failover orchestrat de VM-uri între regiuni. Backup pentru copie la puncte de timp cu retenție lungă. Se completează reciproc.
4De ce Front Door nu rezolvă singur DR-ul?
Front Door mută doar traficul. Replicarea datelor, mutarea compute-ului și identity rămân responsabilități separate.
5Care este cea mai frecventă greșeală în proiectele de DR?
Confundarea backup-ului cu DR-ul și lipsa testării periodice. Un plan netestat nu este un plan.
Temă pentru acasă
Exerciții practice de DR și Business Continuity
Definește RTO/RPO
Alege o aplicație simplă (web + DB) și definește RTO și RPO pornind de la cerințele de business.
Configurează Azure Backup
Creează un vault, aplică o policy și execută un restore test pe un VM de laborator.
Testează ASR
Activează replicarea pentru un VM și execută un test failover către o rețea izolată.
Mini-raport DR
O pagină: ce faci pentru compute, date, trafic și testare. Dacă nu poți răspunde la toate patru, designul nu e matur.
DR nu este doar tehnologie. Este o combinație de arhitectură, operațiuni, securitate, networking, ownership și exercițiu practic.
Concluzie
Un program matur de Disaster Recovery în Azure nu se construiește doar din butoane din portal. Se construiește din obiective clare, design corect, roluri clare, disciplină de testare și alegerea potrivită a serviciilor.
DR nu este doar tehnologie. Este o combinație de arhitectură, operațiuni, securitate, networking, ownership și exercițiu practic.
Ce să faci acum (A09)
- Reascultă rezumatul audio sau recitește secțiunile cheie —salt la audio.
- Verifică notele cu quiz-ul acestei sesiuni.
- Laborator legat: Mini-proiect final + Recap AZ-900 + Carieră.
Opțional: repetă termenii în Studiusau joacă un modul din Game Hub.
Crează-ți profil
Dacă nu te loghezi, parcursul prin sesiuni rămâne doar în acest browser: nu îl vezi pe alt dispozitiv sau în alt browser și îl pierzi dacă ștergi datele site-ului ori folosești incognito.
PIN-ul nu este un cont securizat și nu trebuie să fie aceeași combinație ca parole importante (Microsoft, email bancă). Este doar o etichetă locală + sincronizare pentru progresul din Learn Cloud.
Cu prenume, nume și PIN (4 cifre) îți poți continua cursul oriunde — același cont ca în Game Hub și Realizări(vizite, audio, quiz, lectură).
Ai uitat PIN-ul?
Nu există recuperare automată a PIN-ului. Încearcă combinația salvată sau creează un profil nou cu alt nume/prenume (generând alt ID). Pentru date pe server vezi Ajutor · PIN.
Backup & date locale
Exportul este un fișier JSON pentru arhivă personală; nu îl încărca în locuri publice (poate conține pseudo-identificatori).